
Building evaluation sets that test cultural reasoning in Arabic LLMs
Why token-level benchmarks fail to measure Arabic cultural reasoning, how dialect-aware evaluation datasets improve LLM testing, and why human-reviewed annotation matters for multilingual AI systems.
LLM EVALUATIONARABIC NLPMULTILINGUAL DATASETSCULTURAL CONTEXTAI LOCALIZATION
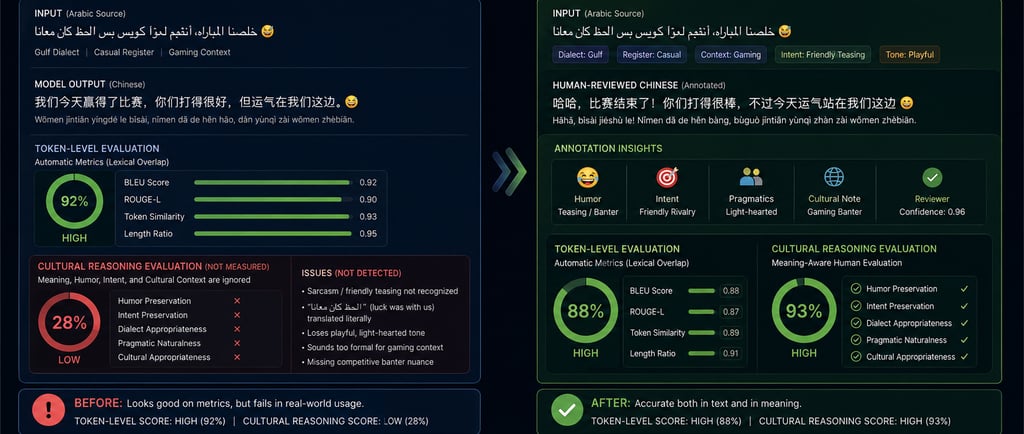

Modern Arabic LLM evaluation still focuses heavily on surface-level correctness.
Most benchmark systems measure:
lexical overlap
token similarity
grammar consistency
literal translation quality
But real-world multilingual AI systems fail in far more complex ways.
Especially in Arabic, models often appear accurate while completely misunderstanding:
dialect behavior
humor
sarcasm
social hierarchy
emotional tone
cultural implication
regional pragmatics
This is why cultural-context evaluation matters.
At SinoArabic Data, many bilingual Arabic-Chinese datasets were structured specifically to expose these meaning-layer failures rather than only measuring token agreement.
Why standard benchmarks are insufficient
Many multilingual benchmarks optimize for clean measurable outputs.
This creates evaluation systems that reward:
literal consistency
predictable sentence structures
normalized language
low-ambiguity examples
But production AI systems rarely operate inside controlled linguistic environments.
Real users communicate through:
dialect mixing
slang
sarcasm
indirect implication
gaming jargon
platform-native expressions
Arabic adds additional complexity because meaning changes significantly across dialects and registers.
A model can achieve strong benchmark scores while still failing in actual deployment environments.
Arabic dialects change model behavior
Arabic is not behaviorally uniform.
The same intent can appear differently across:
Gulf Arabic
Levantine Arabic
Egyptian Arabic
Maghrebi Arabic
Modern Standard Arabic
For example:
A moderation classifier trained mostly on MSA may incorrectly flag Gulf gaming slang as aggression.
A localization model may interpret Levantine sarcasm literally.
A conversational AI system may respond formally to intentionally casual speech.
Without dialect-aware evaluation, these failures remain invisible.
Cultural reasoning is not token prediction
Most current LLM evaluation pipelines still treat language as isolated text prediction.
But Arabic communication often depends on:
social relationships
politeness hierarchy
implied emotional framing
regional expectations
religious sensitivity
humor structure
context inheritance
This means two outputs may appear lexically similar while carrying completely different social meanings.
Cultural reasoning evaluation attempts to measure whether models preserve:
pragmatic intent
emotional interpretation
social appropriateness
dialect compatibility
behavioral consistency
These signals are critical for production AI systems.
Common Arabic LLM failure modes
Across multilingual evaluation workflows, several recurring issues appear repeatedly.
1. Dialect confusion
The model mixes multiple Arabic dialect systems unnaturally.
2. Formality mismatch
Casual conversation becomes rigid Modern Standard Arabic.
3. Humor collapse
The wording survives translation while the joke disappears entirely.
4. Cultural over-normalization
Region-specific expressions get replaced with generic language.
5. Intent distortion
Emotionally supportive dialogue becomes aggressive or cold.
6. Moderation overreach
Gaming slang or playful insults become incorrectly classified as harmful content.
Why human-reviewed annotation matters
Many public datasets lack deep annotation layers.
They often provide only:
source sentence
translated sentence
Without explaining:
intent behavior
sarcasm structure
dialect register
confidence level
cultural adaptation decisions
reviewer rationale
This limits evaluation quality dramatically.
Human-reviewed annotation provides richer supervision signals for:
Arabic LLM evaluation
multilingual RAG systems
moderation classifiers
localization QA
conversational AI
cultural adaptation models
At SinoArabic Data, bilingual alignment workflows often include:
dialect tags
register labels
intent-preservation notes
cultural-context metadata
reviewer confidence scores
failure-mode annotations
These layers help evaluators identify why outputs fail — not only whether they fail.
Evaluation datasets should simulate real interaction
Many benchmarks still rely on isolated sentences.
But production systems interact with:
players
communities
customer-support conversations
live chat systems
multiplayer voice channels
multilingual social environments
Evaluation datasets should therefore include:
ambiguous phrasing
emotional shifts
sarcasm
humor
dialect transitions
UI-context constraints
culturally sensitive references
Otherwise benchmark accuracy becomes disconnected from deployment reality.
The future of Arabic LLM evaluation
As Arabic AI systems become more advanced, evaluation quality will increasingly depend on:
dialect-aware tagging
pragmatic annotation
meaning-layer review
cultural-context metadata
human-reviewed alignment
Future multilingual AI systems will not succeed through token prediction alone.
They must understand how language behaves socially.
This is especially important in:
gaming ecosystems
conversational AI
moderation systems
entertainment platforms
multilingual assistants
culturally adaptive interfaces
Conclusion
Arabic cultural reasoning cannot be measured through surface similarity alone.
High-quality evaluation datasets must test whether models preserve:
intent
emotional meaning
dialect behavior
cultural expectations
pragmatic consistency
Without these layers, benchmark performance can become misleading.
At SinoArabic Data, our focus remains on meaning-level alignment and culturally aware evaluation workflows designed for real multilingual AI deployment environments.