
Annotation you can evaluate before you commit
翎箭标记一名敌人,降低其[25+math.modf((lv-1)/7)*6]%(下一阶:[25+(math.modf((lv-1)/7)+1)*6]%)的双防及闪避,且翎箭对其攻击时,附加[3+math.modf((lv-1)/7)*1]%(下一阶:[3+(math.modf((lv-1)/7)+1)*1]%)的伤害,再额外降低其[20+(lv-1)*3]点(下一级:[20+lv*3])双防,持续
قيام جلاد الجن بوضع علامة على أحد الأعداء، وخفض [25+math.modf((lv-1)/7)*6]%(الدرجة التالية: [25+(math.modf((lv-1)/7)+1)*6]%)من الدفاعي البدني والسحري وكذلك المراوغة، وعند قيام جلاد الجن بمهاجمته، سيكون ذلك مصحوباً بـ [3+math.modf((lv-1)/7)*1]%(الدرجة التالية: [3+(math.modf((lv-1)/7)+1)*1]%) من الضرر
Every sample ships with dialect labels, cultural-context notes, and alignment confidence scores. Format, schema, and review depth — visible here.
intent_flag: pun_survival → FAIL idiom_adjustment: culturally_substituted alignment_score: 0.91
What enterprise sample access includes
Bilingual alignment pairs
Intent-flagged localization pairs
Adversarial cultural-context cases
Each string carries intent-preservation flags: pun survival outcome, honorific mapping decisions, and culturally-adjusted idiom notes with reviewer rationale.
Designed to surface classifier assumptions about Arabic cultural context. Includes adversarial prompts, expected outputs, and failure-mode annotations.
Source and target strings with dialect tags (MSA, Gulf, Levantine), register labels, and per-pair confidence scores from human reviewers.
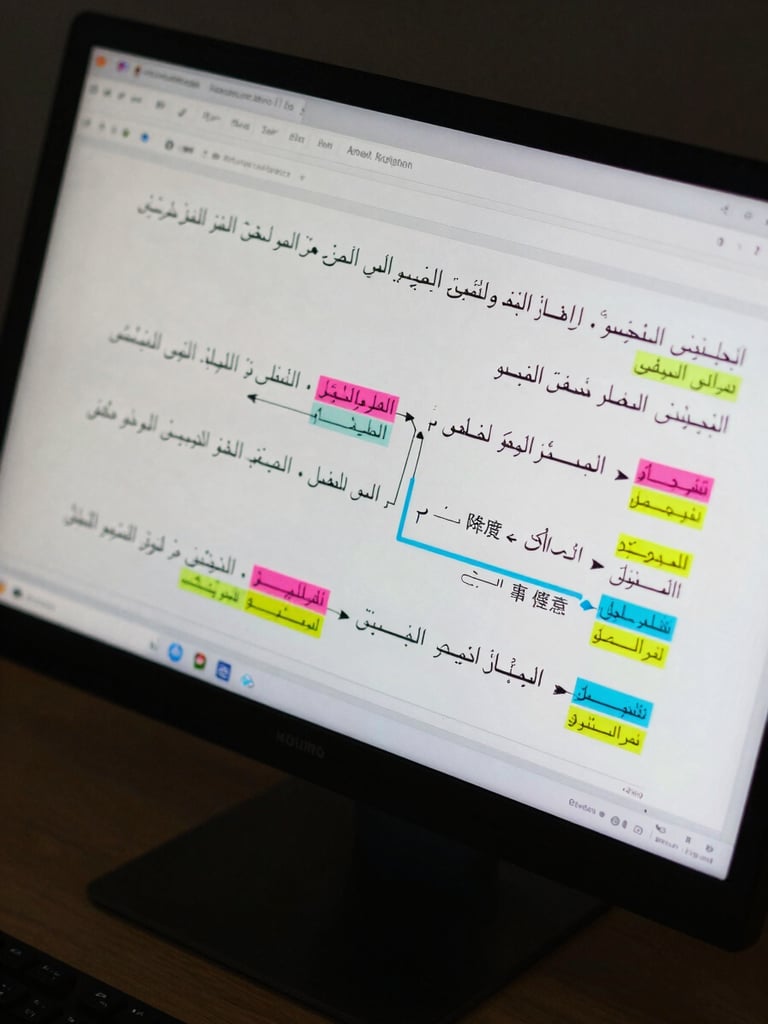
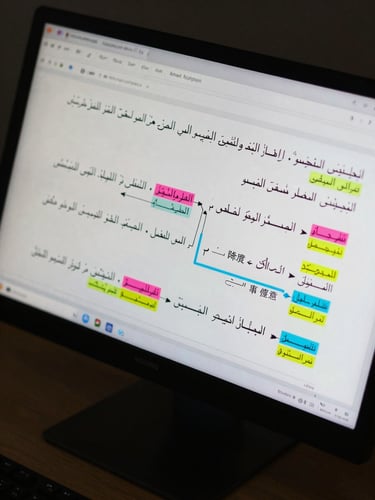
Six fields. Every pair, every review.
Dialect tag and register label identify the Arabic variety. Cultural-context note captures meaning-layer decisions. Alignment confidence reflects human reviewer agreement, not model probability.
Game samples add intent-preservation flags and idiom-adjustment rationale. LLM evaluation samples add adversarial category and expected failure mode.
See the full annotation depth
The full sample pack includes 200 annotated pairs across all three categories with complete schema documentation. Request access to evaluate before any procurement decision.