
What makes a joke survive Arabic localization
Why humor often fails in Arabic game localization, how dialect and cultural context affect player experience, and why human-reviewed annotation matters for AI-ready localization datasets.
GAME LOCALIZATIONARABIC AICULTURAL CONTEXTAI LOCALIZATION
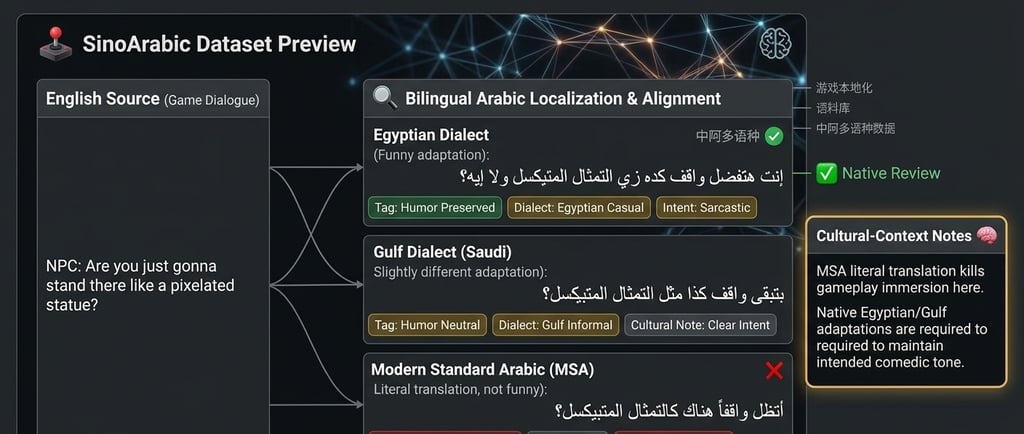
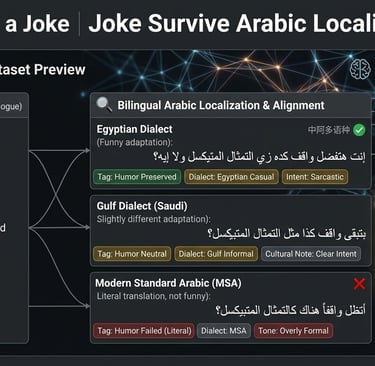
Modern game localization is no longer only about translation accuracy. In multiplayer games, social platforms, voice-chat systems, and mobile live-service titles, humor often becomes one of the first systems to fail during localization.
A sentence can be grammatically correct while still completely collapsing socially, emotionally, or culturally once moved into Arabic.
This becomes even more visible when localization pipelines rely on token-level similarity instead of meaning-level review.
At SinoArabic Data, many of our bilingual Arabic-Chinese localization datasets were built specifically to track these failures.
Why humor breaks during localization
Humor depends on:
dialect familiarity
cultural timing
social hierarchy
sarcasm structure
idiom recognition
emotional tone
platform context
A direct translation may preserve words while destroying intent.
For example, a playful insult in Mandarin Chinese may sound aggressively offensive in Modern Standard Arabic.
Likewise, Arabic dialect humor often relies on rhythm, exaggeration, or cultural references that disappear when normalized into formal Arabic.
This creates a serious issue for:
game localization
AI dialogue systems
multilingual NPC generation
live moderation systems
LLM evaluation benchmarks
The result is often:
awkward dialogue
emotionally flat characters
offensive unintended phrasing
failed jokes
broken immersion
Token-level accuracy is not enough
Many evaluation systems still prioritize:
BLEU similarity
sentence overlap
literal alignment
lexical preservation
But humor survival requires something deeper.
Two sentences may appear highly aligned at token level while completely diverging at the pragmatic level.
This is especially dangerous in:
Arabic multiplayer games
voice-chat moderation
culturally adaptive NPC dialogue
AI-assisted localization pipelines
A localization pipeline that ignores dialect and intent often produces text that technically passes evaluation while failing completely with native players.
Arabic dialects change humor behavior
Arabic is not a single behavioral language.
Humor reception differs heavily across:
Gulf Arabic
Levantine Arabic
Egyptian Arabic
Maghrebi Arabic
Modern Standard Arabic
A joke that feels casual in Levantine Arabic may sound unnatural in Gulf Arabic.
A sarcastic expression that works in Egyptian Arabic may become confusing once converted into MSA.
This is why dialect tagging matters.
In our datasets, localization pairs are often annotated with:
dialect labels
register labels
intent-preservation flags
humor survival outcomes
reviewer confidence scores
cultural-context notes
These annotations allow evaluators to identify where meaning survived — and where it failed.
Cultural-context annotation matters more than literal translation
One of the biggest weaknesses in multilingual datasets is the absence of cultural metadata.
Many public corpora provide only:
source text
target text
But no explanation for:
why a localization choice was made
what social meaning changed
whether a joke survived adaptation
whether honorific behavior shifted
whether slang intensity changed
At scale, these missing signals create major downstream problems for AI systems.
This is especially relevant for:
Arabic LLM evaluation
conversational AI
gaming localization
multilingual RAG systems
moderation classifiers
Without annotation depth, models learn surface alignment instead of pragmatic behavior.
Failure modes we frequently observe
Across Arabic localization datasets, several recurring failure patterns appear repeatedly.
1. Humor collapse
The sentence remains technically correct but loses comedic timing.
2. Register mismatch
A casual gaming interaction becomes overly formal.
3. Cultural mismatch
References understandable in Chinese communities fail entirely for Arabic players.
4. Aggression amplification
Light sarcasm becomes insulting after direct translation.
5. UI-context failure
The localized string exceeds interface limits or breaks interaction flow.
These are not small cosmetic issues.
In live-service games, these failures directly affect:
player retention
immersion
monetization systems
social interaction quality
moderation workload
Human-reviewed alignment still matters
Large language models can accelerate localization workflows.
However, meaning-level review still requires human validation.
Our Arabic-Chinese datasets are manually reviewed specifically because:
intent cannot always be inferred automatically
dialect behavior shifts quickly
slang evolves constantly
sarcasm is context-sensitive
cultural adaptation requires native judgment
Human-reviewed alignment provides stronger signals for:
LLM evaluation
localization QA
AI dialogue systems
multilingual moderation
benchmark construction
Why this matters for future AI systems
As AI-generated dialogue becomes more common inside games and social platforms, localization quality will increasingly depend on:
dialect-aware tagging
cultural-context annotation
pragmatic evaluation
meaning-preservation review
human-validated alignment
Datasets that only optimize for sentence similarity will struggle to support emotionally believable multilingual interaction.
The future of Arabic localization is not only translation.
It is behavioral alignment.
Conclusion
Arabic localization quality cannot be measured through token overlap alone.
To evaluate whether humor survives translation, datasets must include:
dialect metadata
intent-preservation annotation
cultural-context review
human evaluation layers
pragmatic failure tracking
As multilingual AI systems continue expanding into gaming, entertainment, and conversational interfaces, these signals will become essential for building believable and culturally adaptive experiences.
At SinoArabic Data, our focus remains on meaning-layer alignment rather than surface-level similarity — especially for Arabic localization workflows where cultural behavior matters as much as translation accuracy.
Suggested internal links for SEO
Inside the article editor, link these phrases to your own pages:
Arabic NLP datasets → Datasets page
LLM evaluation → Samples page
game localization data → Datasets & Services
human-reviewed alignment → About page
Suggested image placements
Hero Image
Dark annotation interface with Arabic tagging and bilingual localization.
Mid-article image
Before/after localization comparison showing failed humor adaptation.
Final image
Annotated Arabic dataset screenshot with dialect tags and confidence scoring.