
Why Arabic dialect tagging matters in LLM evaluation
Arabic dialect variation creates major challenges for LLM evaluation, localization, and multilingual NLP systems. This article explains why dialect-aware annotation, human-reviewed alignment, and cultural-context tagging are critical for building reliable Arabic AI datasets.
ARABIC NLPLLM EVALUATIONGAME LOCALIZATIONDIALECT ANNOTATIONMULTILINGUAL DATASETSARABIC AIDATASET ENGINEERINGCULTURAL CONTEXTTRANSLATION ALIGNMENTAI LOCALIZATION
Arabic is often treated as a single language in multilingual AI systems. In practice, however, Arabic exists across a wide spectrum of dialects, regional expressions, cultural registers, and context-dependent usage patterns. This creates a major challenge for LLM evaluation, bilingual alignment, and localization workflows.
A model that performs well on Modern Standard Arabic (MSA) may still fail when exposed to Gulf Arabic, Levantine conversational patterns, Egyptian humor, or mixed-register user-generated content. Traditional benchmark accuracy frequently hides these failures because token-level agreement does not necessarily reflect meaning-level understanding.
As Arabic AI adoption expands across gaming, conversational interfaces, customer support systems, and multilingual applications, dialect-aware evaluation is becoming critical infrastructure rather than an optional enhancement.
Why Arabic Dialects Create Evaluation Problems
Unlike many languages with relatively standardized written forms, Arabic operates through overlapping linguistic layers:
Modern Standard Arabic (MSA)
Gulf Arabic
Levantine Arabic
Egyptian Arabic
Maghrebi Arabic
Hybrid digital slang
Romanized Arabic usage
Platform-specific social language
These layers frequently overlap inside the same sentence.
A benchmark built only around MSA often fails to evaluate whether a model truly understands regional meaning, humor, intent, or cultural implication.
For example, two Arabic phrases may appear token-compatible while carrying entirely different pragmatic meanings depending on dialect and context.
This becomes especially problematic in:
LLM evaluation
game localization
multilingual RAG systems
Arabic moderation systems
conversational AI
voice chat translation
community platforms
Without dialect tagging, many of these failures remain invisible during evaluation.
Token-Level Accuracy Is Not Enough
Many evaluation pipelines still prioritize BLEU-style similarity metrics or direct token overlap. While these methods can measure surface similarity, they often miss deeper linguistic failure modes.
A translation can appear technically correct while still failing in:
humor preservation
tone consistency
social hierarchy
honorific usage
regional appropriateness
cultural context
gameplay intent
For example, a localized game dialogue line may preserve literal meaning while completely collapsing the intended comedic tone for Gulf Arabic users.
Similarly, a conversational AI assistant may produce grammatically correct Arabic while sounding culturally unnatural or regionally inconsistent.
These failures are difficult to detect without human-reviewed dialect-aware annotation.
The Role of Dialect Metadata in Arabic NLP
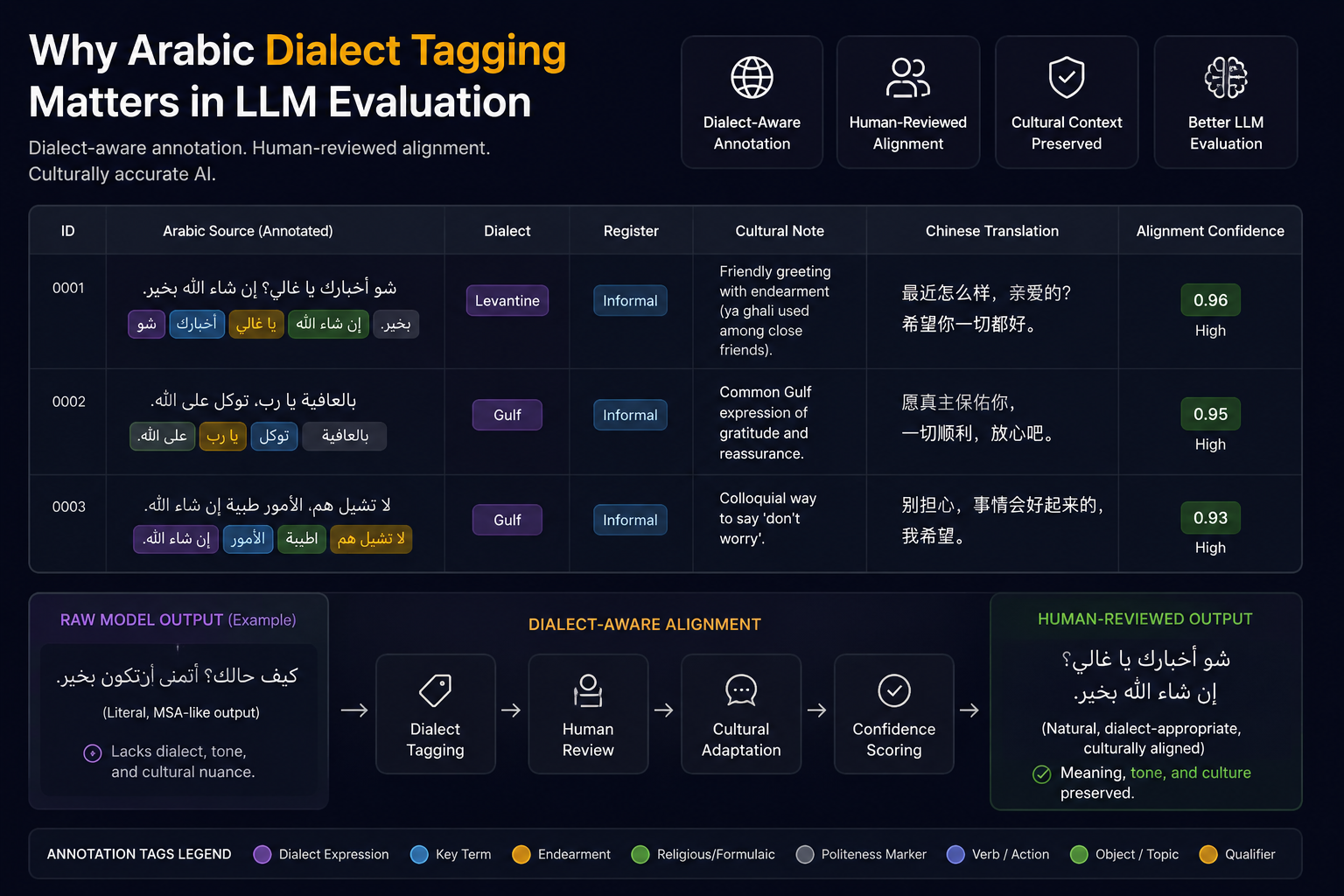
Dialect tagging introduces structured linguistic context into evaluation datasets.
Instead of treating Arabic as a single homogeneous language, dialect-aware annotation captures:
regional variety
register level
conversational tone
idiomatic intent
cultural substitution
reviewer rationale
alignment confidence
This additional metadata dramatically improves the usefulness of multilingual datasets for both training and evaluation.
In high-quality Arabic NLP corpora, annotation layers may include:
Field
Purpose
Dialect Tag
Identifies regional Arabic variety
Register Label
Formal, casual, social, gaming, etc.
Cultural Note
Flags context-sensitive meaning
Intent Flag
Tracks humor, sarcasm, gameplay intent
Alignment Confidence
Human-reviewed pair quality
Reviewer Notes
Explains adaptation decisions
These annotation layers allow evaluation teams to identify not only whether a model produced the correct words, but whether it preserved the correct meaning.
Failure Cases Standard Benchmarks Often Miss
One of the largest weaknesses in multilingual evaluation is the inability to detect culturally-aware failure modes.
Some common examples include:
Dialect Confusion
A model mixes Gulf vocabulary with Levantine sentence structure, creating unnatural output.
Humor Collapse
A joke survives literal translation but loses its cultural punchline entirely.
Honorific Failure
The translation ignores social hierarchy or formality expectations.
Localization Tone Drift
A UI string sounds technically correct but inconsistent with the game’s tone or target audience.
Cultural Mismatch
An idiom is translated directly instead of culturally adapted.
These are not rare edge cases. They appear frequently in Arabic localization and multilingual LLM deployment.
Unfortunately, many evaluation datasets fail to expose them because they lack dialect-aware annotation layers.
Why Human-Reviewed Alignment Still Matters
Automated alignment pipelines are useful for scale, but Arabic evaluation still requires human review at the meaning layer.
Human reviewers can identify:
pragmatic mismatch
sarcasm failure
tone inconsistency
culturally inappropriate substitutions
dialect mixing
semantic drift
gameplay-context errors
This becomes especially important in:
Arabic game localization
voice-chat moderation
conversational AI
LLM benchmarking
bilingual dataset construction
Human-reviewed bilingual alignment remains one of the strongest signals of dataset reliability in Arabic NLP workflows.
Building Better Arabic Evaluation Data
As multilingual AI systems continue expanding into Arabic-speaking markets, evaluation methodology must evolve beyond simple translation matching.
Reliable Arabic evaluation datasets increasingly require:
dialect-aware tagging
human-reviewed alignment
cultural-context annotation
intent-preservation review
localization-focused validation
multilingual metadata structure
Datasets designed with these principles expose failure modes that standard benchmarks often overlook.
This is particularly important for organizations building:
Arabic LLMs
multilingual assistants
localization pipelines
Arabic moderation systems
gaming platforms
culturally-aware AI products
Conclusion
Arabic dialect variation is not a minor linguistic detail. It directly impacts how AI systems understand meaning, intent, humor, and cultural context.
As Arabic NLP systems become more sophisticated, dialect-aware evaluation is no longer optional. High-quality human-reviewed multilingual datasets are becoming essential for reliable LLM evaluation, localization quality assurance, and cross-cultural AI deployment.
The future of Arabic AI will depend not only on larger models, but on better linguistic infrastructure built around real-world language variation.