
Building evaluation sets that test cultural reasoning in Arabic LLM systems
Why token-level benchmarks fail to measure Arabic cultural reasoning in LLM systems. Learn how dialect tagging, pragmatic annotation, humor detection, and adversarial evaluation sets improve Arabic NLP evaluation quality.
LLM EVALUATIONARABIC NLPDATASET METHODOLOGY
Large language model evaluation in Arabic still relies heavily on token-level evaluation. BLEU overlap, lexical agreement, and surface translation accuracy remain the dominant benchmarks across many multilingual NLP pipelines.
But Arabic linguistic behavior is not purely lexical. A sentence can achieve near-perfect token overlap while completely failing in dialect appropriateness, humor preservation, pragmatic meaning, social register, and conversational intent.
This is especially visible in Arabic game localization, multilingual chat systems, and Arabic conversational AI. At SinoArabic Data, our evaluation methodology focuses on meaning-layer validation. Explore our specialized Arabic NLP datasets to see how we build production-ready test suites.
Why token-level evaluation fails in Arabic
Arabic contains multiple linguistic layers that cannot be measured through lexical overlap alone. These include:
Dialect variation & regional phrasing
Cultural references & indirect humor
Social hierarchy markers & religious sensitivity
Sarcasm, irony, and conversational politeness
A model may produce a grammatically correct sentence while still sounding unnatural, culturally inappropriate, or contextually incorrect to native speakers.
For example, a Gulf Arabic phrase used as game localization data may be translated literally into Modern Standard Arabic or Chinese while losing its competitive tone, teasing intent, or social familiarity. Traditional benchmarks often score this output highly despite the practical failure.
What cultural reasoning evaluation actually measures
Meaning-aware Arabic evaluation requires more than translation comparison. It requires annotation layers that expose:
1. Dialect identification
Advanced Arabic dialect tagging helps determine whether the generated output matches the intended regional usage (Gulf, Levantine, Egyptian, Iraqi, or MSA). Without dialect-aware evaluation, models often collapse regional variation into generic Arabic.
2. Register and tone preservation
Arabic communication changes significantly depending on formality, age group, gaming culture, and humor intensity. A localization pipeline must evaluate whether the output preserves the original social tone.
3. Pragmatic meaning
Pragmatics measure what the sentence actually means within context (teasing, challenge framing, sarcasm, or emotional implication). Pragmatic failure is one of the largest blind spots in multilingual LLM evaluation.
4. Cultural-context alignment
Some phrases require cultural substitution rather than literal translation. Evaluation datasets should measure whether cultural adaptation occurred and whether the final output sounds native.

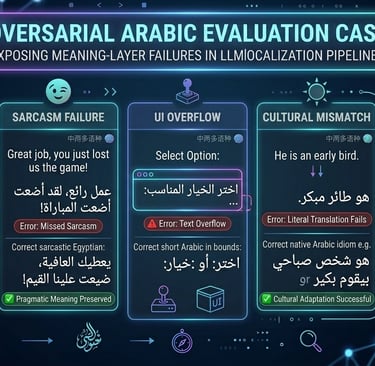
Building adversarial Arabic evaluation sets
Most public benchmarks are too clean. Real-world Arabic localization contains fragmented sentences, slang, hybrid English-Arabic usage, emoji logic, and UI character limits. High-quality Arabic evaluation sets should intentionally include failure-triggering cases.
At SinoArabic Data, our adversarial evaluation samples are designed to expose dialect confusion, humor collapse, and tone mismatch. These are real production problems in Arabic NLP systems that we solve using custom bilingual alignment datasets.
Human-reviewed evaluation remains essential
Automatic scoring systems cannot reliably detect cultural mismatch or regional authenticity. This is why human-reviewed annotation layers remain critical for Arabic LLM evaluation. Our annotation workflows include dialect metadata, confidence scoring, and intent-preservation flags. The goal is not simply translation correctness; the goal is usable linguistic behavior.
Evaluation datasets should reflect deployment reality
Arabic AI systems increasingly operate in competitive environments like multilingual gaming, voice chat, moderation systems, and multilingual RAG systems. Evaluation sets must therefore measure real deployment risks. A benchmark that ignores culture, dialect, and pragmatics cannot accurately predict production performance.
Conclusion
Arabic NLP evaluation cannot stop at token overlap. Models that appear successful on traditional metrics may still fail native users in real interaction environments. Meaning-aware evaluation requires dialect-aware tagging, pragmatic annotation, and adversarial testing.
As Arabic LLM deployment grows, evaluation methodology must evolve. If you are building enterprise AI solutions, you can request a dataset sample from our team to see how we measure actual linguistic understanding.