
Human-reviewed Arabic alignment pipelines for multilingual AI systems
How human-reviewed Arabic alignment pipelines improve multilingual AI systems, Arabic NLP evaluation, dialect-aware annotation, and game localization quality beyond token-level matching.
ARABIC NLPALIGNMENT METHODOLOGYMULTILINGUAL ADATASET ENGINEERING
Modern multilingual AI systems rely heavily on aligned bilingual datasets. Yet many alignment pipelines still depend on automated matching methods that optimize for surface similarity instead of meaning preservation.
For Arabic NLP systems, this creates a serious problem.
Arabic is not a single uniform language layer. Dialect variation, register shifts, cultural references, sarcasm, humor, and pragmatic context all affect whether an aligned pair is actually usable for model training or evaluation.
A token-level match may appear technically correct while still failing semantically.
This becomes especially visible in:
Arabic game localization
multilingual conversational AI
Arabic moderation systems
dialect classification pipelines
LLM evaluation frameworks
cross-cultural dialogue systems
Human-reviewed alignment workflows help solve these failures by introducing linguistic review layers that automated pipelines often miss.
Why automated Arabic alignment often fails
Most alignment systems prioritize:
token similarity
sentence structure overlap
statistical probability
embedding proximity
These methods work reasonably well for generic translation tasks. However, they frequently break under culturally-sensitive Arabic content.
Examples include:
Gulf vs Levantine dialect confusion
honorific mismatch
idiom collapse
sarcasm normalization
pragmatic tone loss
UI string overflow
gameplay humor distortion
In multilingual AI systems, these failures can silently propagate into:
training datasets
evaluation benchmarks
retrieval pipelines
localization systems
moderation models
This is why human-reviewed Arabic alignment remains critical for high-quality multilingual AI infrastructure.
Meaning-level alignment matters more than token overlap
A strong bilingual pair is not simply a sentence pair with similar wording.
It must preserve:
pragmatic intent
cultural meaning
emotional tone
gameplay function
UI constraints
dialect consistency
For example, an Arabic localization string used in a multiplayer game may technically translate correctly while still sounding unnatural to native players.
Human reviewers can detect issues such as:
culturally inappropriate phrasing
dialect drift
register inconsistency
mistranslated humor
broken payment terminology
social interaction mismatch
These problems are difficult to detect using BLEU scores or embedding similarity alone.
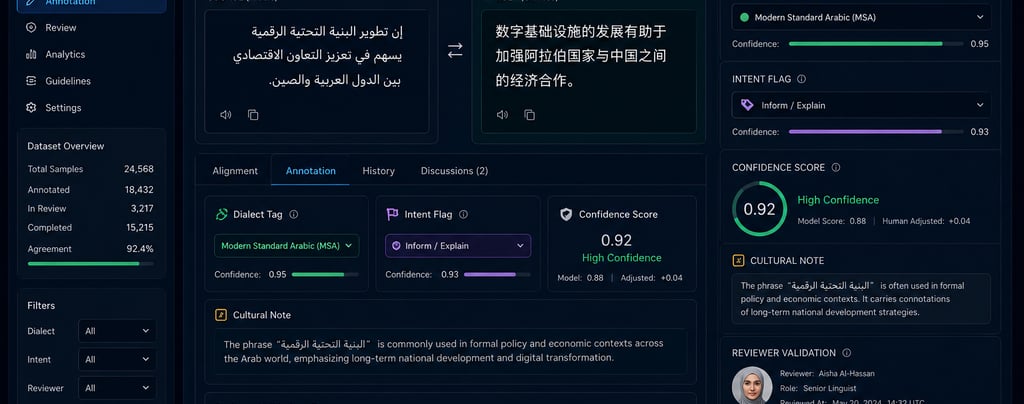
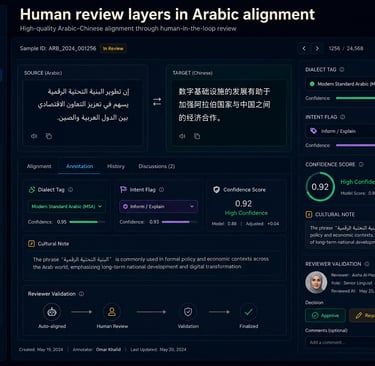
Human-reviewed annotation layers
A robust Arabic alignment pipeline often includes structured annotation fields such as:
dialect tag
register label
intent preservation flag
cultural-context note
reviewer confidence score
alignment quality score
Additional metadata may include:
sarcasm detection
idiom substitution rationale
UI length warnings
localization constraints
adversarial evaluation markers
These annotation layers help multilingual AI systems understand not only what was translated, but how meaning changed during alignment.
Arabic-Chinese alignment complexity
Arabic-Chinese bilingual alignment introduces additional challenges because both languages differ structurally and culturally.
Difficult areas include:
indirect social expressions
honorific systems
metaphor translation
game economy terminology
humor adaptation
player interaction styles
In many cases, literal translation creates unnatural or misleading Arabic output.
Human-reviewed alignment pipelines help preserve functional equivalence instead of literal wording.
This distinction is especially important for:
Arabic game localization
AI dialogue systems
multilingual LLM evaluation
conversational AI safety testing
Why enterprise AI teams need reviewed alignment datasets
As Arabic AI systems become more commercially important, low-quality bilingual alignment becomes increasingly expensive.
Poor alignment quality can produce:
unreliable evaluation results
degraded model behavior
localization QA failures
moderation inconsistencies
hallucinated cultural assumptions
Human-reviewed Arabic datasets provide stronger reliability for:
LLM evaluation
multilingual retrieval systems
conversational AI
Arabic moderation
localization QA
dialect-aware training
This is particularly important when building production-level AI systems rather than research-only prototypes.
Conclusion
Arabic alignment quality cannot be measured through token similarity alone.
Meaning-level review, dialect awareness, cultural annotation, and human validation remain essential for multilingual AI systems operating in Arabic environments.
As Arabic NLP infrastructure continues to mature, human-reviewed alignment pipelines will become increasingly important for evaluation reliability, localization quality, and culturally-aware AI behavior.